LEANN: Revolúcia v lokálnom RAG vyhľadávaní
Ako indexovať milióny dokumentov na notebooku bez straty úložiska.
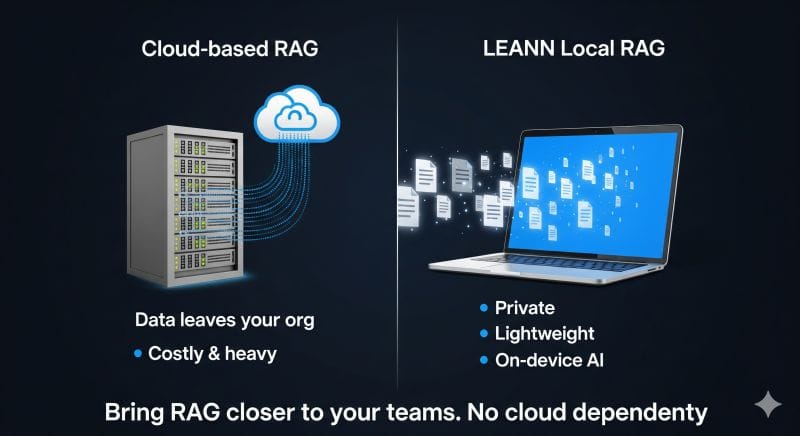
Moderné AI nástroje ako Retrieval-Augmented Generation (RAG) sú často viazané na cloudové služby. Chcete semantické vyhľadávanie vo vašich osobných dátach – e-mailoch, chat históriách, prehliadači či kóde – ale bez toho, aby ste odovzdali všetko do rúk veľkým tech gigantov? A ešte k tomu s obmedzeným úložiskom na vašom notebooku?
Tu prichádza LEANN, open-source nástroj, ktorý mení pravidlá hry. Pozrieme sa hlbšie na to, čo LEANN je, ako presne funguje, ako sa porovnáva s tradičnými vector databázami a ako ho môžete hneď vyskúšať. Všetko je založené na najnovšom výskume z Berkeley Sky Computing Lab a praktickom kóde z GitHubu.
Čo je LEANN a prečo by ste ho mali poznať?
LEANN (Low-Storage Efficient Approximate Nearest Neighbor) je inovatívna vector databáza navrhnutá špeciálne pre osobné zariadenia s obmedzenými zdrojmi, ako sú notebooky alebo telefóny. Predstavte si, že môžete indexovať a vyhľadávať v 60 miliónoch textových chunkov (napr. z Wikipédie) len v 6 GB úložiska namiesto tradičných 201 GB. To je úspora až 97 %! A to bez straty presnosti – vyhľadávanie zostáva rýchle, presné a 100 % súkromné, pretože všetko beží lokálne, bez cloudu.
Tento projekt, licencovaný pod MIT, vyšiel z laboratória Berkeley Sky Computing Lab a je dielom výskumníkov ako Yichuan Wang a Zhifei Li. Jeho hlavný cieľ? Umožniť RAG (kde AI model dopĺňa odpovede relevantnými dátami z vašej knižnice) na "každom" – od PDF dokumentov cez e-maily (Apple Mail), prehliadačovú históriu (Chrome), chaty (WeChat, iMessage, ChatGPT, Claude) až po živé dáta cez MCP protokol (Slack, Twitter) alebo codebase s AST-aware chunkingom pre jazyky ako Python či Java.

Integruje sa s LLM providermi ako Ollama, Hugging Face alebo OpenAI-kompatibilnými API (napr. Groq, vLLM).
V skratke: LEANN premieňa váš laptop na výkonný RAG systém, kde môžete semanticky vyhľadávať vo svojich osobných dátach bez obáv o súkromie alebo náklady na cloud. A to všetko s podporou metadátového filtrovania, grep vyhľadávania a dynamického batchingu pre GPU efektivitu.
Ako LEANN funguje?
Podrobné vysvetlenie pod kapotou. LEANN nie je obyčajná vector databáza – je to chytrý grafový index, ktorý sa spolieha na selektívnu rekalkuláciu embeddingov na požiadanie namiesto ich plného ukladania. To je kľúčová inovácia: tradičné systémy ukladajú embeddingy (husté vektory reprezentujúce text) pre všetky dáta, čo zaberie obrovské miesto. LEANN ich ukladá len minimálne (alebo vôbec) a počíta ich len pre tie uzly grafu, ktoré sa naozaj preskúmajú počas vyhľadávania. Poďme sa rozobrať krok za krokom.
1. Offline fáza: Budovanie indexu
- Embedding a grafová konštrukcia: Najprv sa pre všetky dáta (napr. textové chunky po 256 tokenoch) spočítajú embeddingy pomocou modelu ako Contriever (768 dimenzií). Potom sa postaví HNSW graf (Hierarchical Navigable Small World), kde každý uzol reprezentuje chunk a hrany spájajú približne najbližšie susedy. Tento graf sa vytvorí pomocou nástrojov ako FAISS.
- Pruning grafu (orezanie hrán): Tu prichádza mágia úspory úložiska. LEANN aplikuje high-degree preserving pruning, tzn. identifikuje "hub" uzly (top 2 % s najvyšším stupňom, t.j. najviac spojené), pretože tieto sa navštevujú až 5x častejšie. Pre bežné uzly sa orezajú hrany na nižší stupeň (napr. z 18 na 9), ale huby si zachovajú plnú konektivitu. Graf sa uloží v kompaktnej CSR forme (Compressed Sparse Row), čo zaberie menej ako 5 % pôvodného úložiska (napr. 3,8 GB pre 60M chunkov). Embeddingy sa vymažú – uložia sa len surové texty a metadáta.
- Voliteľné caching: Ak máte extra miesto, uložte PQ-komprimované embeddingy pre huby (ďalších ~2 GB), čo urýchli vyhľadávanie.
2. Online fáza: Vyhľadávanie (query time)
- Embedding query: Používateľova otázka sa embedne.
- Grafová traversácia: Začína sa best-first search (BFS) z entry pointu. Systém prechádza vrstvami HNSW grafu, priorizujúc kandidátov podľa vzdialenosti k query.
- Selektívny recompute: Namiesto ukladania embeddingov sa pre navštívené uzly rekalkulujú za letu z surového textu. BFS navštívi len malý podmnožinu (polylogaritmicky v veľkosti N), takže recompute je efektívny.
- Two-level search: Pre minimalizáciu recomputov sa použije hybridný prístup: Najprv aproximovaná vzdialenosť cez PQ-komprimované embeddingy (pre široké skenovanie), potom exact recompute len pre top a% kandidátov (napr. 10 %). To redukuje recomputy o 40 %.
- Dynamic batching: Rekalkulácie sa hromadia do batchov (napr. 64 uzlov) pre plné využitie GPU, bez výrazného oneskorenia BFS.
- Výstup: Top-k výsledkov s metadátami, pripravených na RAG (napr. vstup do Llama modelu).
Celý proces trvá pod 2 sekundy pri 90 % recall@3, s latenciou dominantne v recompute (76 % času). To je ideálne pre edge zariadenia – žiadne I/O bottleneck ako v diskových systémoch.
Porovnanie s inými vector DB: Prečo LEANN vyhráva v úložisku?
Tradičné vector DB ako HNSW, DiskANN či IVF (z FAISS) sú skvelé pre dátacentrá, ale na osobných zariadeniach zlyhávajú kvôli úložisku. LEANN ich prekonáva v úspore (až 50x menší), pri zachovaní presnosti a akceptovateľnej latencie. Pozrime sa na tabuľku porovnania na benchmarku RPJ-Wiki (60M chunkov, 76 GB surových dát):

Zdroj: Experimenty na NVIDIA A10 a M1 Mac. LEANN prekonáva IVF-Recompute o 21–200x v latencii vďaka grafovej štruktúre (polylog N vs. lineárne). Na macOS (M1) je pomalší o 2–3x, ale stále pod 5 s. Pre porovnanie úložiska na osobných dátach (e-maily, chaty):

LEANN exceluje v scenároch, kde úložisko je bottleneck – napr. na mobile.
Slabiny? Konštrukcia indexu vyžaduje dočasne plné embeddingy (neskôr vymazané).
Benchmarky a reálne výsledky: Čísla, ktoré presviedčajú
Na benchmarkoch ako NQ, TriviaQA, GPQA a HotpotQA dosahuje LEANN 90 % Recall@3 (t.j. zachytí 90 % skutočných top-3 susedov) s latenciou 1–2 s.
Downstream RAG s Llama-3.2-1B: EM 29.1 % na NQ (vs. 19.2 % BM25), F1 60.4 % na TriviaQA. Ablácie ukazujú: Two-level search zrýchli o 1.4x, dynamic batching o ďalších 1.76x celkovo. Pruning zachováva kvalitu lepšie ako náhodné orezanie (1.18x lepšie). Na osobných dátach (e-maily o jedle z DoorDash, chaty o víkendových plánoch) LEANN vracia relevantné chunky s metadátami (napr. dátum, autor), čo tradičné DB často prehliadnu.
Ako začať s LEANN: Praktický návod
Inštalácia je jednoduchá cez uv (Python manager). Predpoklad: Python 3.12+.
CLI pre osobné dáta (napr. e-maily na macOS):
leann build moje_emaily --docs ~/Library/Mail/V10
leann ask moje_emaily "Aké jedlo som objednal cez Uber Eats?" --interactivePríklad: Rýchly RAG chat:
from leann import LeannBuilder, LeannSearcher, LeannChat
INDEX_PATH = "moj_index.leann"
# Budovanie
builder = LeannBuilder(backend_name="hnsw")
builder.add_text("LEANN šetrí 97% úložiska oproti tradičným DB.", metadata={"zdroj": "blog"})
builder.build_index(INDEX_PATH)
# Vyhľadávanie
searcher = LeannSearcher(INDEX_PATH)
results = searcher.search("úspora úložiska", top_k=1, metadata_filters={"zdroj": {"==": "blog"}})
# Chat
chat = LeannChat(INDEX_PATH, llm_config={"type": "ollama", "model": "llama3.2:1b"})
odpoved = chat.ask("Ako LEANN funguje?", top_k=1)
print(odpoved)Inštalácia:
curl -LsSf https://astral.sh/uv/install.sh | sh
git clone https://github.com/yichuan-w/LEANN.git leann
cd leann
uv venv && source .venv/bin/activate
uv pip install leann # Alebo uv sync --extra diskann pre pokročiléPre MCP (živé dáta): Nastavte tokeny (napr. SLACK_BOT_TOKEN) a spustite servery.
Integrácia s Claude Code: claude mcp add leann-server – leann_mcp.
Záver: Budúcnosť lokálneho AI je tu. LEANN nie je len ďalší nástroj – je to most k plne súkromnému, prenosnému AI. S 97 % úsporou úložiska, bez straty presnosti a podporou širokej škály dát ho robí ideálnym pre developerov, výskumníkov či bežných používateľov.
Budúcnosť? Rozšírenie na multi-hop vyhľadávanie, menšie modely alebo dokonca image search. Ak chcete experimentovať, začnite na GitHub alebo si prečítajte dokument na arXiv.