Stavba RAG systému na platforme IBM:
Praktický príklad s Granite a Docling:
Ak ste sa niekedy zamýšľali, ako zlepšiť odpovede vašich AI modelov tým, že im dáte prístup k externým znalostiam bez toho, aby ste museli model celý pretrénovať, potom je Retrieval - Augmented Generation (RAG) presne to, čo hľadáte.
Pozrieme sa na to, ako postaviť takýto systém na platforme IBM, využívajúc open-source nástroje ako Granite (rodina veľkých jazykových modelov od IBM) a Docling (nástroj na inteligentné spracovanie dokumentov). Ako príklad použijeme Jupyter notebook z repozitára Granite Snack Cookbook, ktorý slúži ako skvelý štartovací bod pre začiatočníkov aj pokročilých vývojárov.
Článok je rozdelený do krokov, kde vysvetlíme nie len ako to urobiť, ale aj prečo – princíp za každým krokom. Predpokladom sú základné znalosti Pythonu a Jupyteru. Na konci nájdete tipy na rozšírenie a potenciálne pasce.
Čo je RAG a prečo ho používať na IBM platforme?
Predtým, ako sa pustíme do kódu, krátky teoretický základ. RAG je technika, ktorá kombinuje retrieval (vyhľadávanie relevantných informácií z veľkého korpusu dát) s generáciou (vytváranie odpovedí pomocou LLM).
Princíp je jednoduchý: namiesto toho, aby model "hádal" na základe tréningových dát (ktoré môžu byť zastarané), najprv vyhľadáme relevantné dokumenty, pridáme ich do promptu a potom necháme model generovať odpoveď.
Výsledok? Presnejšie, aktuálnejšie a kontextovo bohatšie odpovede – ideálne pre aplikácie ako chatboti, výskumné nástroje alebo interné vyhľadávače.
Prečo IBM?
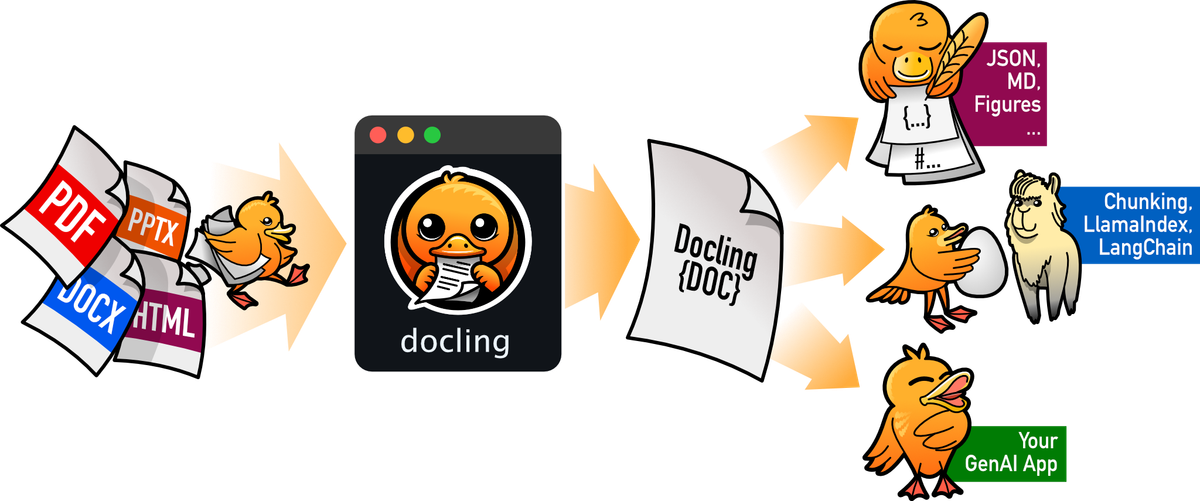
IBM ponúka Granite, open-source rodinu modelov optimalizovaných pre podnikové použitie (napr. Granite 3B alebo 8B pre embeddingy a generáciu). Sú efektívne, bezpečné a integrovateľné s IBM Watsonx platformou. Navyše, Docling pridáva špeciálne schopnosti na spracovanie komplexných dokumentov (PDFy s tabuľkami, obrázkami), čo je často slabina iných nástrojov.
Všetko je open-source, takže to môžete spustiť lokálne na laptope bez cloudových nákladov.
V notebooku sa zameriavame na jednoduchý pipeline: spracujeme PDF dokumenty, vytvoríme vektory, uložíme ich a potom odpovedáme na otázky.
Celý systém beží v Pythone s knižnicami ako LangChain, FAISS a Hugging Face Transformers.
Krok 1: Príprava prostredia – Položte základy
Princíp: Každý RAG systém začína stabilným prostredím. Tu inštalujeme závislosti, aby sme zabezpečili kompatibilitu a efektivitu.
Prečo? Bez správnych verzií sa embeddingy môžu pokaziť alebo retrieval zlyhať. V notebooku začíname inštaláciou balíkov cez pip:
!pip install docling docling-core docling-renderers granite-embedding-docling-rag langchain faiss-cpu transformers torch- Docling: IBM nástroj na konverziu dokumentov do štruktúrovaného formátu (text, tabuľky, obrázky).
Princíp: Používa AI na "porozumenie" layoutu PDF, nie len OCR – to znamená, že zachytí štruktúru (nadpisy, odseky), čo zlepšuje kvalitu chunkov. - Granite embedding: Model na vytváranie vektorov (napr. ibm-granite/granite-embedding-1.0-110m-multilingual).
Princíp: Embeddings sú numerické reprezentácie textu v multidimenzionálnom priestore, kde podobné texty sú blízko seba (cosine similarity). - LangChain a FAISS: LangChain orchestruje pipeline (retrieval + generation), FAISS je rýchly vector store pre lokálne vyhľadávanie.
Tip: Ak bežíte na GPU, pridajte faiss-gpu pre rýchlosť. V notebooku sa to spúšťa v Colab-e, ale funguje aj lokálne.
Krok 2: Spracovanie dokumentov s Docling – Extrakcia znalostí z chaosu
Princíp: Dokumenty (najmä PDF) sú často "neštruktúrované" – text je zmiešaný s tabuľkami a obrázkami. Docling ich parsuje do Markdownu alebo JSON, čím vytvára čisté, hierarchické dáta.
Prečo? Dobré chunkovanie (rozdelenie na malé časti) je kľúčom k presnému retrievalu – veľké bloky sú neefektívne, malé strácajú kontext.
V notebooku:
Extrahujte text do Markdownu:
md_content = result.document.export_to_markdown()Načítajte dokument:
from docling.document_converter import DocumentConverter
from pathlib import Path
converter = DocumentConverter()
source = Path("path/to/your/document.pdf")
result = converter.convert(source)Princíp za Docling: Používa hybridný prístup – rule-based parsing + ML modely (napr. na detekciu tabuliek). Výstup je MD súbor, ktorý zachováva štruktúru, napr.:
# Nadpis
Text odseku...
| Tabuľka | Stlpec1 | Stlpec2 |
|---------|---------|---------|
| Riadok1 | Hodnota | Hodnota |To umožňuje inteligentné chunkovanie: rozdelenie na odseky alebo tabuľky, nie na náhodné vety. V notebooku sa MD delí na chunks veľkosti 500 znakov s overlapom 50 (pre zachovanie kontextu).
Krok 3: Generovanie embeddingov s Granite – Vytvorenie vektorového "DNA" textu
Princíp: Embeddings transformujú text do vektorov, ktoré umožňujú matematické porovnanie (napr. dot product). Granite model je multilingual a optimalizovaný pre dlhé texty, čo znižuje halucinácie v RAG.
V notebooku:
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Chunkovanie
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_text(md_content)
# Embeddings
embeddings = HuggingFaceEmbeddings(
model_name="ibm-granite/granite-embedding-1.0-110m-multilingual"
)Princíp: Model (110M parametrov) beží na CPU/GPU a produkuje 768-rozmerné vektory.
Prečo Granite? Je trénovaný na rôznorodých dátach, vrátane kódu a technických textov, takže lepšie zachytáva sémantiku než univerzálne modely ako BERT.
Výstup: Zoznam vektorov pre každý chunk.
Krok 4: Ukladanie do vector store – Vaša "knižnica" vektorov
Princíp: Vector store indexuje embeddingy pre rýchle vyhľadávanie (O(1) čas). FAISS používa aproximované nearest neighbors (ANN), čo je efektívne pre milióny vektorov.
V notebooku:
from langchain.vectorstores import FAISS
vector_store = FAISS.from_texts(chunks, embeddings)
vector_store.save_local("faiss_index")Princíp: FAISS buduje index (napr. IVF – Inverted File), kde sa vektory hashujú do "búsk".
Prečo lokálne? Pre demo – v produkcii použite Pinecone alebo IBM Watsonx pre škálovateľnosť.
Krok 5: Retrieval – Nájdenie relevantných kúskov
Princíp: Otázku embeddnite rovnakým modelom, potom vyhľadajte top-k podobných chunkov (k=3-5). To pridá kontext do promptu, čím sa vyhýbame halucináciám. Ide o to, ako RAG systém "nájde" relevantné informácie z dokumentov a použije ich na odpoveď, namiesto toho aby si to AI vymýšľala z hlavy.
1. Čo je embedding a prečo ho robíme pre otázku?
- Predstav si, že text (či už dokument alebo otázka) je ako slovo v slovníku. Embedding je ako premena toho slova na súradnice v priestore (napr. [0.5, -0.2, 1.3, ...] – dlhý zoznam čísel). Tieto čísla zachytávajú "zmysel" textu: podobné slová (napr. "pes" a "mačka") majú blízke súradnice.
- Prečo rovnakým modelom? Dokumenty sme už zmenili na takéto vektory (embeddingy) pomocou modelu Granite. Ak zmeníme otázku na vektor rovnakým modelom, budú v tom istom "priestore" – ako keby sme ich dali na rovnakú mapu. Inak by sme ich nemohli porovnať (napr. jablko s pomarančom).
Príklad:
Otázka: "Aká je teplota varu vody?"
Embedding: Model ju zmení na vektor, povedzme [0.8, 0.1, -0.4, ...] (v skutočnosti stovky čísel).2. Vyhľadávanie top-k podobných chunkov (k=3-5)
- Chunky sú malé kúsky textu z dokumentov (napr. odsek alebo tabuľka, veľkosť okolo 500 znakov).
- V vector store (ako FAISS) máš tisíce týchto chunkov ako body na mape. Teraz vezmeš vektor otázky a povieš: "Nájdi mi 3-5 najbližších bodov (chunkov) k tomuto bodu."
- Ako meriame podobnosť? Používa sa niečo ako "cosine similarity" – meria, ako veľmi sú vektory "v rovnakom smere" (uhol medzi nimi). Čím menší uhol, tým podobnejšie (napr. 95% podobnosť = super relevantné).
- Prečo k=3-5? Nie príliš málo (aby nebola odpoveď chudobná), nie príliš veľa (aby prompt nebol príliš dlhý a model sa nezamotal).
Príklad pokračovanie:
- Dokumenty majú chunky ako:
- Chunk 1: "Voda vrie pri 100 °C na mori." (vektor blízky k otázke)
- Chunk 2: "Teplota varu na vrchole hory klesá." (stredne blízky)
- Chunk 3: "Varíme vodu v hrnci." (menej relevantný)
- Systém vyberie top-3: Chunky 1, 2 a možno iný o tlaku (ak je relevantný).
3. Pridanie kontextu do promptu
- Tieto vybrané chunky sa "natlačia" do promptu (správy), ktorú pošleš LLM (veľkému jazykovému modelu ako Granite).
Potom prompt vyzerá asi takto:
"Na základe tohto kontextu odpovedz na otázku:
Kontext: [Chunk 1] [Chunk 2] [Chunk 3]
Otázka: Aká je teplota varu vody?
Odpoveď:"
- Model tak "vidí" fakty priamo z tvojich dokumentov, nie len svoju "pamäť" z tréningu.
4. Prečo sa tým vyhneme halucináciám?
- Halucinácie nastávajú, ak AI vymýšľa nesprávne veci (napr. povie "Voda vrie pri 50 °C", lebo si to "spomenulo" z chybného tréningu).
- S kontextom z relevantných chunkov sa model opiera o skutočné dáta – ako keby si dal žiakovi učebnicu namiesto toho, aby odpovedal z hlavy.
Výsledok: Presnejšia odpoveď, napr. "Podľa dokumentu vrie voda pri 100 °C na úrovni mora."
Celý tento krok (retrieval) trvá milisekundy, pretože FAISS je super rýchly na hľadanie susedov v tom vektorovom priestore.
V notebooku:
query = "Vaša otázka tu?"
retriever = vector_store.as_retriever(search_kwargs={"k": 3})
relevant_docs = retriever.get_relevant_documents(query)Princíp: Cosine similarity meria uhol medzi vektormi – čím menší, tým podobnejšie.
Výstup: Zoznam textov, ktoré sa pridajú do promptu ako
"Kontext: [chunk1] [chunk2]".
Krok 6: Generácia s Granite LLM – Spojenie retrievalu s kreativitou
Princíp: Použite LLM na generáciu odpovede na základe augmentovaného promptu. Granite Code alebo Instruct modely sú tu ideálne – sú inštrukčne trénované na presné odpovede.
V notebooku:
from langchain.llms import HuggingFacePipeline
from langchain.chains import RetrievalQA
from transformers import pipeline
# LLM pipeline
llm = HuggingFacePipeline.from_model_id(
model_id="ibm-granite/granite-3.0-8b-instruct",
task="text-generation",
pipeline_kwargs={"max_new_tokens": 200}
)
# RAG chain
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True
)
response = qa_chain({"query": query})
print(response["result"])Princíp: "Stuff" chain vloží všetky relevantné docs do jedného promptu.
Prečo Granite?
Je bezpečný (menej toxický), podporuje dlhé kontexty a je open-source, takže bez licenčných poplatkov.
Výstup: Odpoveď s citáciami na zdroje (relevant_docs).
V notebooku to celé zaberie menej ako 100 riadkov kódu, ale princípy sú univerzálne. Testujte na vlastných PDF (napr. technické manuály) a sledujte metriky ako BLEU score pre presnosť.
Tipy na rozšírenie:
- Multi-modal: Docling podporuje obrázky – pridajte vision modely ako Granite Vision.
- Škálovanie: Integrujte s Watsonx.ai pre cloud deployment.
- Pasce: Sledujte chunk veľkosť (príliš veľké = pomalé, príliš malé = strata kontextu). Aktualizujte index pravidelne pre nové dáta.
Ak chcete experimentovať, forkujte repozitár a pridajte svoje dáta.



