DocTags: Nový štandard od IBM

Ak ste sa niekedy trápili s chaotickými PDF súbormi, ktoré sa odmietajú dať spracovať vašim veľkým jazykovým modelom (LLM), viete, o čom hovorím.
Tie nekonečné tabuľky, ktoré sa rozpadnú do bezbrehej textovej kaše, obrázky bez kontextu alebo nadpisy, ktoré sa stratia v štruktúre – to všetko je nočná mora pre akýkoľvek AI pipeline.
Ale dobré správy: IBM Research práve prinieslo riešenie, ktoré to mení. DocTags, nový markup štandard, ktorý je ako XML na steroidoch, špeciálne navrhnutý pre éru generatívnej AI. V tomto príspevku sa ponoríme do sveta DocTags, preskúmame jeho mechanizmy, výhody a ako ho integrovať do vašich projektov.
Prečo DocTags? Problém, ktorý rieši.. V dnešnej dobe sú dokumenty všade – od firemných reportov cez vedecké články až po právne zmluvy. Ale väčšina z nich je v neštruktúrovaných formátoch ako PDF alebo skeny, ktoré sú pre AI ako čítanie knihy bez obsahu.
Tradičné nástroje na extrakciu textu (napr. PyMuPDF alebo Tesseract) často strácajú štruktúru: tabuľky sa zmenia na nekonečné riadky textu, obrázky na bezduché bloky a hierarchia (nadpisy, podnadpisy) sa rozplynie.
DocTags to rieši elegantne. Je to ľahký, čitateľný markup formát, inšpirovaný XML, ktorý explicitne oddeluje textový obsah od vizuálnej štruktúry. Výsledok? Dokumenty, ktoré sú pripravené na priame kŕmenie do LLM, bez potreby zložitých post-procesov. IBM to vyvinulo ako súčasť open-source projektu Docling, ktorý je určený na end-to-end konverziu dokumentov pre gen AI.
Podľa IBM, DocTags minimalizuje ambiguítu a zvyšuje spoľahlivosť spracovania o desiatky percent, čo je ideálne pre aplikácie ako RAG (Retrieval-Augmented Generation) alebo agentické systémy.
História a kontext: Ako vznikol DocTags v IBM ekosystéme? DocTags nie je len náhodný výmysel – je to výsledok dlhoročného výskumu IBM v oblasti dokumentovej inteligencie. V septembri 2025 IBM vydalo model Granite-Docling, vizuálno-jazykový model (VLM) s 258 miliónmi parametrov, ktorý je postavený na architektúre Idefics3, ale s kľúčovými úpravami pre dokumenty.
Tento model je súčasťou širšej rodiny Granite, open-source LLM od IBM, optimalizovaných pre podnikové úlohy. Projekt Docling, na ktorom DocTags stojí, je open-source toolkit (dostupný na GitHub pod DS4SD/docling), ktorý parsuje rôzne formáty – od PDF a DOCX cez PPTX, XLSX, HTML až po audio a video súbory. DocTags slúži ako výstupný formát, ktorý zachytáva všetko: layout, tabuľky, vzorce, obrázky a kódové bloky. Je navrhnutý tak, aby bol lokálny a bezpečný – žiadne externé API volania, ideálny pre citlivé dáta v air-gapped prostrediach.
Okrem štandardnej verzie existuje aj ultra-kompaktná SmolDocling (256M parametrov), určená pre edge zariadenia, kde efektivita je kľúčová.
IBM to prezentovalo ako "end-to-end document understanding s jedným malým modelom", čo znamená, že celý proces – od obrázku stránky po štruktúrovaný výstup – prebieha v jednom kroku.
Ako DocTags funguje? Hlboký ponor do štruktúry: DocTags je hierarchický formát, ktorý reprezentuje dokument ako strom tagov. Každý tag má jasnú sémantiku, čo umožňuje LLM ľahko navigovať štruktúrou. Tu je prehľad kľúčových prvkov:
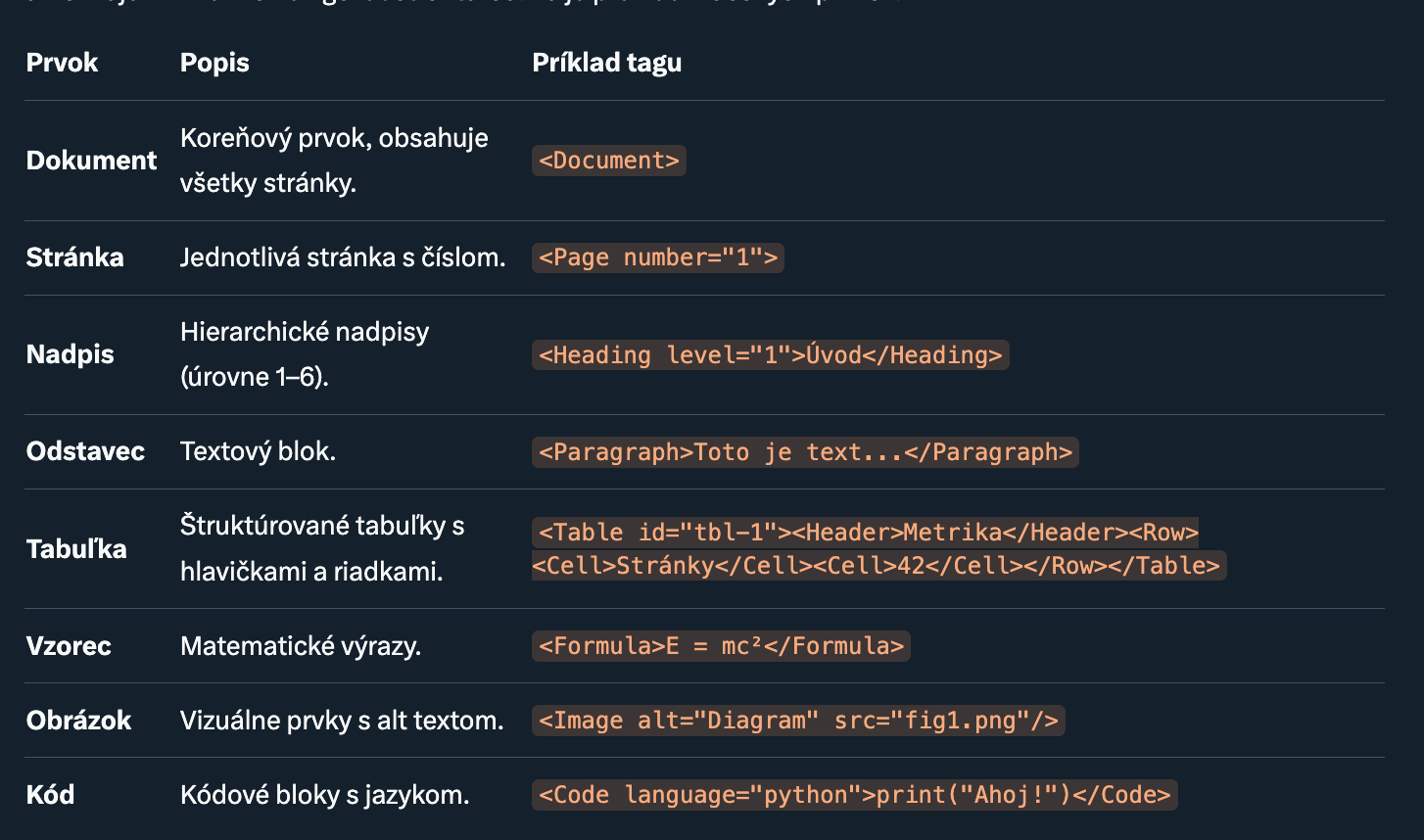
Táto štruktúra zachytáva čítacie poradie a layout, čo je obrovský krok vpred oproti plochému textu. Na rozdiel od Markdownu, ktorý je skôr vizuálny, DocTags je sémantický – tagy explicitne označujú význam, nie len formátovanie.
Príklad výstupu pre jednoduchý dokument:xml
<Document>
<Page number="1">
<Heading level="1">Úvod do DocTags</Heading>
<Paragraph>Tento štandard od IBM mení spracovanie PDF.</Paragraph>
<Table id="tbl-1">
<Header>Prvok</Header><Header>Výhoda</Header>
<Row><Cell>Tagy</Cell><Cell>Jasná štruktúra</Cell></Row>
</Table>
<Image alt="Graf štruktúry" src="structure.png"/>
</Page>
</Document>Tento formát je ľahko parsovateľný v Pythone cez ElementTree alebo v podobných knižniciach.
Integrácia s Granite-Docling: Od obrázku k tagom v jednom kroku. Srdcom DocTags je model Granite-Docling-258M, dostupný na Hugging Face. Tento VLM analyzuje obrázok stránky (napr. z PDF) a priamo generuje DocTags.
Proces:
- Vstup: Obrázok alebo PDF stránka.
- Analýza: Model detekuje layout (tabuľky, text, obrázky) pomocou vizuálneho enkódovania.
- Generovanie: Výstup ako XML tagy, optimalizovaný pre LLM.
- Export: Možnosti ako DocTags, Markdown, HTML alebo JSON.
V Docling toolkitu to ide cez jednoduchý Python kód:python
from docling.document_converter import DocumentConverter
# Konverzia URL alebo lokálneho súboru
source = "https://arxiv.org/pdf/2408.09869"
converter = DocumentConverter()
result = converter.convert(source)
# Export do DocTags
doctags_xml = result.document.export_to_doctags()
print(doctags_xml)Alebo cez CLI:bash
docling --format doctags --pipeline vlm --vlm-model granite_docling https://arxiv.org/pdf/2206.01062 > vystup.doctagsTo je super pre RAG 2.0 pipeline, kde štruktúrované dáta zlepšujú retrieval a znižujú halucinácie.
Výhody DocTags: Prečo by ste mali prejsť naň hneď? DocTags nie je len formát – je to katalyzátor pre lepšie AI aplikácie. Tu je prehľad výhod:
- Efektivita pre LLM: Tagy umožňujú deterministické promptovanie, napr. "Súhrnuj len <Paragraph> tagy" alebo "Extrahuj dáta z <Table>". To šetrí tokeny a zvyšuje presnosť.
- Zachovanie štruktúry: Žiadne straty v tabuľkách či obrázkoch – všetko je explicitne označené.
- Integrácia s frameworkmi: Priamo kompatibilné s LangChain, LlamaIndex, Haystack alebo Crew AI.
- Lokálne spustenie: Žiadne cloud závislosti, ideálne pre GDPR a bezpečnosť.
- Multimodálny support: Podporuje obrázky, vzorce a kód, čo rozširuje možnosti pre multimodálne LLM.
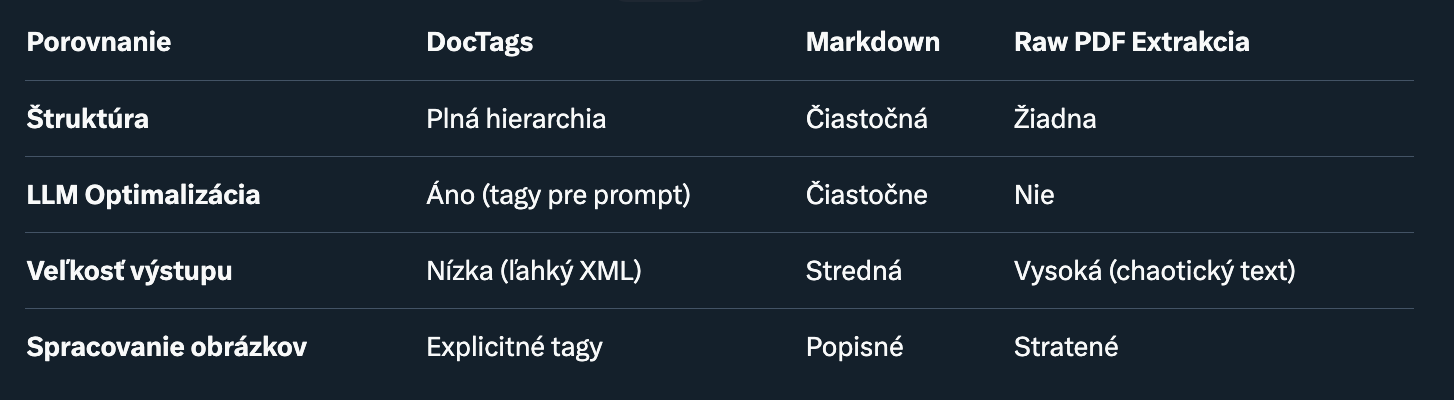
V porovnaní s inými nástrojmi (napr. LayoutLM alebo Unstructured.io) je DocTags kompaktnejší a LLM-centrický – menej post-procesingu, viac priameho použitia.
Praktické príklady: Ako začať dnes: Predstavte si, že extrahujete tabuľky z finančného reportu. Po konverzii do DocTags môžete parsovať XML:
python
import xml.etree.ElementTree as ET
root = ET.fromstring(doctags_xml)
tables = root.findall(".//Table")
for tbl in tables:
headers = [c.text for c in tbl.findall(".//Header/Cell")]
rows = [[c.text for c in row.findall("Cell")] for row in tbl.findall(".//Row")]
print(f"Hlavičky: {headers}\nRiadky: {rows}")Výsledok? Čisté dáta, pripravené na pandas alebo priamo do LLM pre analýzu.
Pre pokročilých: Integrujte s Granite-Docling cez Hugging Face pre lepšiu detekciu layoutu v skenoch.
Budúcnosť DocTags: Kam smeruje tento štandard? IBM plánuje rozšíriť DocTags o podporu pre viac jazykov, lepšiu detekciu rukopisu a integráciu s agentickými frameworkmi. S rastom open-source komunity (už tisíce stiahnutí na GitHub) sa očakáva, že sa stane de facto štandardom pre dokumentové AI. V ére, kde AI musí rozumieť svetu papiera, je DocTags mostom do budúcnosti.
Čas na upgrade vášho dokumentového pipelineDocTags od IBM nie je len technický trik – je to revolúcia v tom, ako AI chápe naše dokumenty. Ak ste vývojár, stiahnite si Docling z GitHub, vyskúšajte Granite-Docling na Hugging Face a uvidíte rozdiel sami.



