IBM Granite-Docling
Predstavte si toto: Máte hromadu starých PDF správ, zmlúv, vedeckých článkov alebo dokonca skenovaných kníh, ktorými chcete nakŕmiť svoj AI systém. Ale namiesto čistého textu dostanete chaotickú zmes obrázkov, pokrivených tabuliek a nečitateľných vzorcov. Frustrujúce, však?
V dnešnej dobe, keď sú všade RAG (Retrieval-Augmented Generation) a agentické AI workflowy efektívne spracovanie dokumentov nie je len výhodou – je to nutnosť.
A tu prichádza IBM Granite-Docling, open-source nástroj, ktorý to všetko rieši jedným elegantným balíkom. Ponorme sa do sveta Doclingu a jeho najnovšieho dieťaťa – modelu Granite-Docling-258M - vizuálno-jazykový model (VLM)
Prečo spracovanie dokumentov stále bolí? Krátky pohľad do minulosti.. Pamätáte si časy, keď OCR (optické rozpoznávanie znakov) znamenalo hodiny ladenia chýb a tabuľky, ktoré sa rozpadli ako domček z kariet? Tradičné nástroje ako Tesseract alebo Adobe Acrobat boli skvelé na základné úlohy, ale v ére veľkých jazykových modelov (LLM) nestačia. Dokumenty sú plné vizuálnych prvkov – layoutu, obrázkov, kódových blokov, chemických vzorcov – a AI ich potrebuje v štruktúrovanom formáte, aby mohla generovať relevantné odpovede.
Podľa nedávneho technického reportu od IBM Research Zurich, až 80 % podnikových dát je "neštruktúrovaných", väčšinou v PDF. Tu do arény vstupuje Docling – open-source projekt iniciovaný IBM, ktorý sa stal súčasťou LF AI & Data Foundation.
Jeho cieľ? Zjednodušiť konverziu dokumentov do formátov ako Markdown, JSON alebo HTML, pripravených na generatívnu AI. A s príchodom Granite-Docling-258M v septembri 2025 sa to posunulo na novú úroveň: end-to-end konverzia s vizuálnym jazykovým modelom (VLM), ktorý zachováva štruktúru bez straty detailov.
Čo je Docling? Základný kameň open-source dokumentovej AI. Docling nie je len ďalší parser – je to kompletný ekosystém na "pripravenie dokumentov pre gen AI". Začal ako interný projekt IBM Research, ale dnes je dostupný na GitHube s MIT licenciou a tisíckami stiahnutí.
Jeho hlavné piliere:
- Podpora širokej škály formátov: PDF, DOCX, PPTX, XLSX, HTML, dokonca audio (WAV, MP3) a obrázky (PNG, TIFF, JPEG). To zahŕňa aj WebVTT pre tituly videí.
- Pokročilá analýza: OCR pre skenované dokumenty, detekcia layoutu (vrátane čítacieho poradia), tabuľky, kódové bloky, matematické vzorce a klasifikácia obrázkov.
- Výstupné formáty: Markdown pre jednoduchosť, HTML pre web, DocTags (nový štandard od IBM pre štruktúrované tagy) alebo lossless JSON pre presnosť.
- Lokálne spustenie: Žiadne cloud závislosti – ideálne pre citlivé dáta v air-gapped prostrediach.
Čo je nové v roku 2025? Beta verzia štruktúrovanej extrakcie informácií, nový layout model "Heron" pre rýchlejšie parsovanie PDF (až 2x rýchlejší) a MCP server pre agentické aplikácie. Prichádza aj podpora pre extrakciu metadát (názov, autori, jazyk), porozumenie grafov (stĺpcové, koláčové) a chemických štruktúr.
Ako hovorí komunita:
"Docling je švajčiarsky nôž pre dokumenty"
Granite-Docling-258M: Kompaktný gigant s 258 miliónmi parametrov. Vydaný 17. septembra 2025 pod Apache 2.0 licenciou na Hugging Face. Tento multimodálny VLM je navrhnutý špeciálne pre konverziu dokumentov: berie obrázok stránky a produkuje štruktúrovaný text, ktorý zachováva pôvodný layout.
Prečo je revolučný?
- Architektúra: Kombinácia vizuálneho enkodéra a textového dekodéra, optimalizovaná pre efektivitu. S len 258M parametrami beží na bežnom hardvéri – CPU, GPU alebo dokonca WebGPU v prehliadači.
- Školenie: Trénovaný na obrovskom datasete vrátane syntetických dokumentov, pokrýva viacero jazykov (vrátane slovenčiny, češtiny a ázijských). Podporuje multilingual OCR a parsing.
- Schopnosti:
- Konverzia dokumentov: Celé PDF do Markdownu s zachovaním sekcií.
- Tabuľky a kód: Rozpoznáva a exportuje ako HTML tabuľky alebo syntax-highlighted kód.
- Vzorce a obrázky: Matematica do LaTeX, obrázky s captioningom.
- Multimodalita: Integruje audio ASR pre transkripciu.
V benchmarkoch ako OmniDocBench dosahuje edit distance 0.138 (nižšie = lepšie), čo je porovnateľné s komerčnými systémami, ale s 10x menšou veľkosťou.
Testovali ho na bangalských dokumentoch a chvália presnosť v tabuľkách – ideálne pre lokálne NLP úlohy.
Porovnanie s konkurenciou? Granite-Docling je ako DeepSeek-OCR: oba sa zameriavajú na kompresiu vizuálnych tokenov, ale IBM verzia exceluje v štruktúre a enterprise nasadení.
Ako to nainštalovať a použiť? Praktický návod krok za krokom.. Docling je jednoduchý na spustenie – žiadne zložité setupy. Začnime s Dockerom, pretože je to najrýchlejšie pre testovanie.
1. Docker cesta (ai/granite-docling). Ak chcete plnú silu Granite, stiahnite oficiálny obraz:
docker pull ai/granite-docling:latestSpustite s GPU podporou (ak máte NVIDIA):
docker run -it --rm --gpus all \
-v $(pwd)/docs:/docs \
ai/granite-docling:latest \
python -m docling.document_converter \
--input /docs/moj_pdf.pdf \
--output /docs/vystup.md \
--pipeline vlm --vlm-model granite_docling-258mToto spracuje PDF a výstupne dá Markdown s tabuľkami ako HTML. Pre CPU variant použite tag cpu.ibm.com2.
Python inštalácia
pip install doclingPotom v skripte:
python
from docling.document_converter import DocumentConverter
from docling_core.models.layout_model import LayoutModel
converter = DocumentConverter(layout_model=LayoutModel.HERON) # Nový rýchly model
result = converter.convert("https://arxiv.org/pdf/2408.09869.pdf")
print(result.document.export_to_markdown())Pre Granite integráciu pridajte --vlm-model granite_docling v CLI alebo cez API.github.com3.
CLI pre rýchle testy
docling --pipeline vlm --vlm-model granite_docling moj_dokument.pdfVýstup? Čistý Markdown, pripravený na LLM ako Grok alebo Llama.
Pre pokročilých: WebGPU verzia beží priamo v prehliadači – skvelé pre demo bez inštalácie.
Integrácie: Ako to zapojiť do vášho AI pipeline.. Docling nie je osamelý vlk – integruje sa s top frameworkmi:
- LangChain/LlamaIndex: Priamo ako loader pre RAG.
Príklad: DoclingLoader nahrá PDF do vektorov s layout metadátami. - Haystack/Crew AI: Pre agentické workflowy, kde agenti extrahujú entity z DocTags.
- Granite 4.0: Nová verzia LLM od IBM (október 2025) sa perfektne hodí – malé, efektívne modely pre on-prem.
V praxi: Nahrajte PDF do RAG systému, kde Granite-Docling extrahuje tabuľky ako JSON. Výsledok? AI odpovede s presnými číslami namiesto halucinácií.
Podľa Medium článku, toto "super-charguje RAG 2.0" o 30-50 % v presnosti.
Výhody, benchmarky a potenciálne muchy
Výhody:
- Efektivita: 258M params = beží na laptope, spracuje 200k strán denne na A100 GPU.
- Open-source: Žiadne licenčné poplatky, plná prispôsobiteľnosť.
- Multijazyčnosť: Testované na ázijských a európskych jazykoch, vrátane slovenčiny.
- Bezpečnosť: Lokálne, bez odosielania dát do cloudu.
Benchmarky:
V Fox benchmarku dosahuje 97 % presnosť pri 10x kompresii vizuálnych tokenov. Porovnateľné s GOT-OCR 2.0, ale s lepšou štruktúrou.
Nevýhody? Ešte beta pre niektoré funkcie ako grafy, a pre veľmi komplexné chemické štruktúry je odporúčané doplniť UniMER. Ale komunita rastie – od workshopov po testy v Banglade.
Budúcnosť: Kam smeruje Granite-Docling?
IBM sľubuje viac: Plná podpora pre chart understanding, metadata extrakciu a dokonca integráciu s Granite 4.0 pre end-to-end agentov. Ako súčasť Granite rodiny, toto je len začiatok – očakávajte hybridné modely pre video a 3D dokumenty do 2026.
Vyskúšajte to dnes a transformujte svoje dáta. Granite-Docling nie je len nástroj – je to most medzi chaotickými dokumentmi a inteligentnou AI. Či ste developer, data scientist alebo podnikateľ, toto open-source riešenie vám ušetrí hodiny a zvýši presnosť vašich systémov. Stiahnite si ho z GitHubu, vyskúšajte CLI príkaz a zdieľajte svoje skúsenosti na X s #DoclingGranite.
Podrobné Benchmarky Modelu IBM Granite-Docling-258M
Tento kompaktný vizuálny jazykový model (VLM) s 258 miliónmi parametrov bol vydaný IBM v septembri 2025 a je optimalizovaný pre konverziu dokumentov v rámci knižnice Docling.
Jeho výkon bol testovaný na viacerých štandardných datasetech a frameworkoch, kde sa porovnáva najmä s predchodcom SmolDocling-256M-Preview (tiež od IBM). Benchmarky pokrývajú oblasti ako rozpoznávanie layoutu, OCR (optické rozpoznávanie znakov), kód, rovnice, tabuľky a multimodálne úlohy.
Dáta pochádzajú z oficiálnej modelovej karty na Hugging Face a sú validované nezávislými testami. Granite-Docling dosahuje konzistentné zlepšenia – až o 50 % v niektorých metrikách – pri zachovaní nízkej veľkosti modelu, čo ho robí ideálnym pre lokálne nasadenie.Použijem tabuľky na prehľadnosť. Všetky metriky sú zhodnotené pomocou frameworku docling-eval (pre dokumentové úlohy) a lmms-eval (pre multimodálne benchmarky).
Nižšie je rozdelené podľa kategórií.
1. Rozpoznávanie Layoutu (Layout Recognition). Táto časť testuje schopnosť modelu identifikovať štruktúru dokumentu (napr. nadpisy, odseky, obrázky). Dataset: Interné IBM syntetické dokumenty.
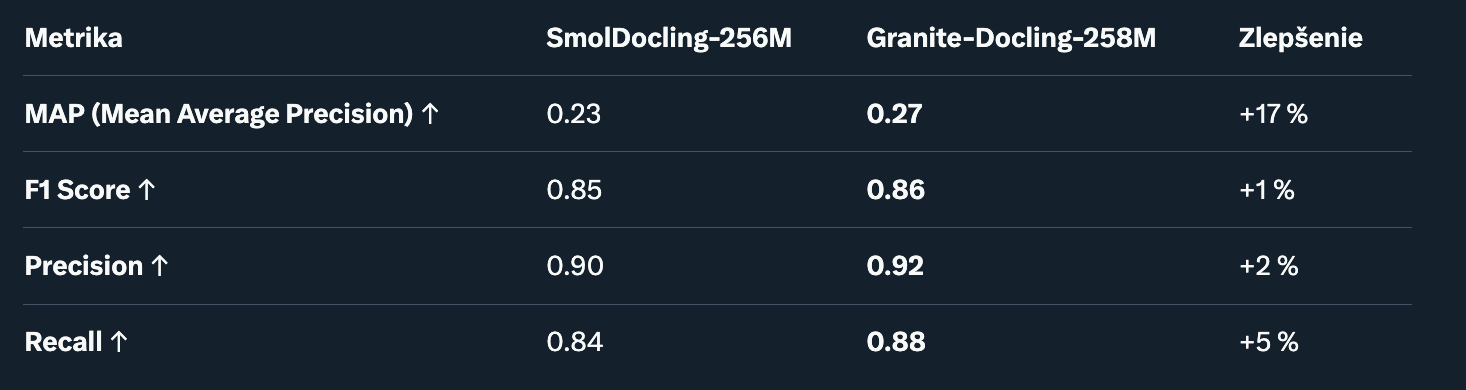
Poznámka: Granite-Docling lepšie zachytáva čítacie poradie a vizuálne prvky, čo znižuje chyby v komplexných PDF.
2. Plnohodnotné OCR (Full Page OCR). Testuje presnosť extrakcie textu z celých stránok, vrátane ručne písaného alebo skenovaného obsahu.
Dataset: Štandardné OCR datasety ako SynthDoctr.
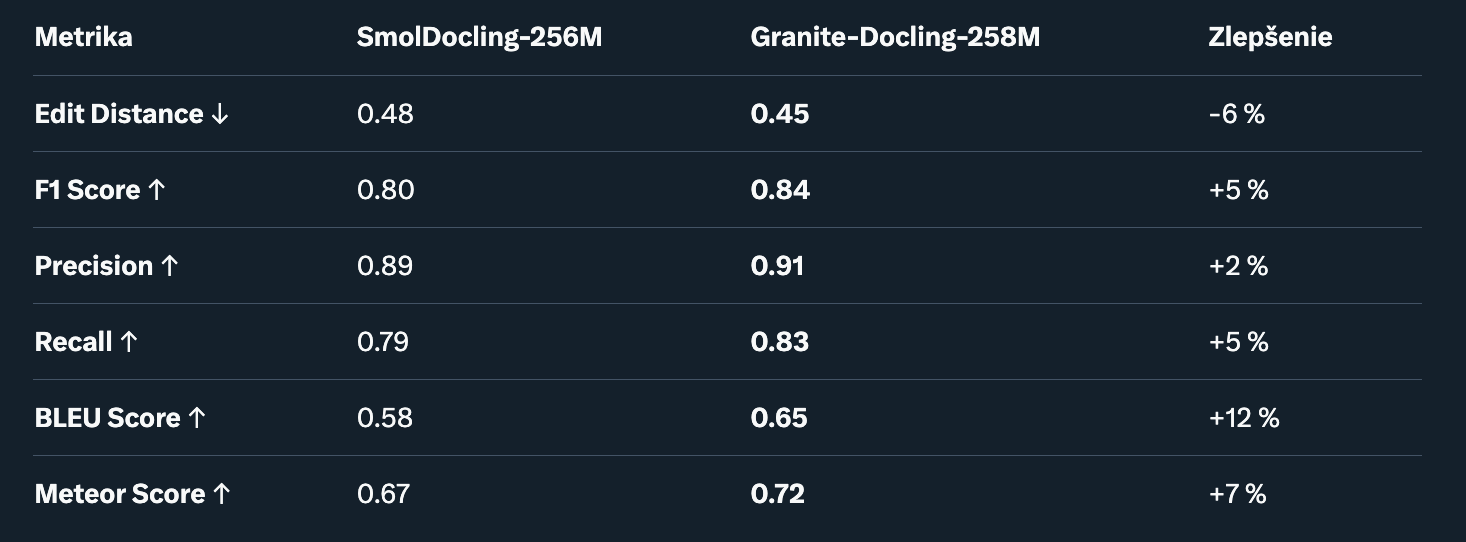
Poznámka: BLEU a Meteor merajú sémantickú podobnosť – Granite-Docling produkuje plynulejší text, ideálne pre RAG aplikácie.
3. Rozpoznávanie Kódu (Code Recognition). Špecializovaný test na extrakciu kódu z obrázkov alebo PDF (napr. z technických dokumentov).
Dataset: SynthCodeNet.
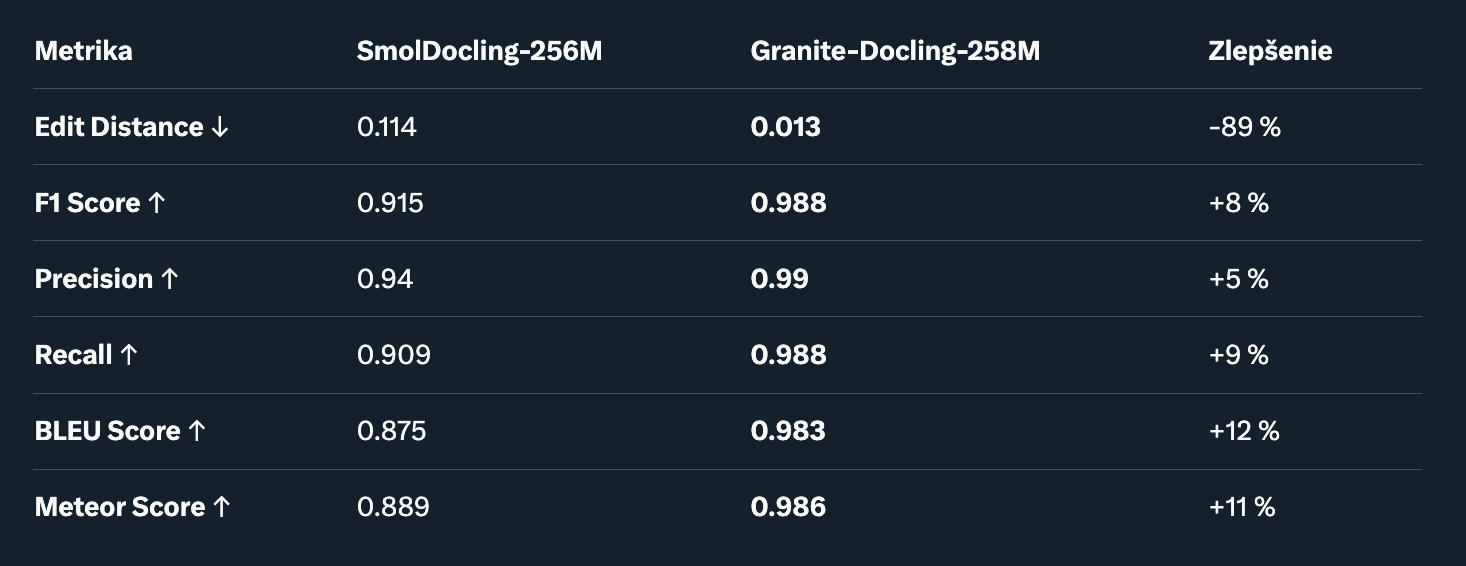
Poznámka: Dramatické zlepšenie v edit distance – Granite-Docling takmer dokonale transkribuje kód, čo je kľúčové pre developer tools.
4. Rozpoznávanie Rovníc (Equation Recognition). Test na konverziu matematických vzorcov do LaTeX.
Dataset: SynthFormulaNet.
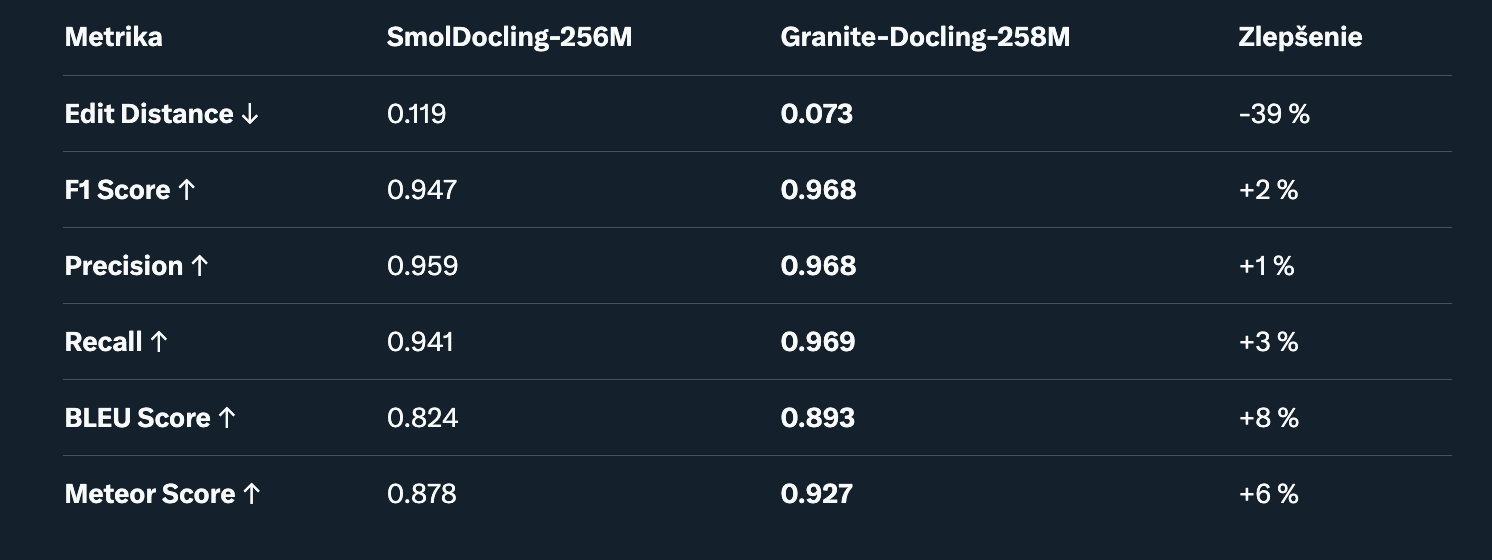
Poznámka: Lepšia štruktúrna presnosť pre komplexné rovnice, užitočné v vedeckých textoch.
5. Rozpoznávanie Tabuľok (Table Recognition). Fokus na finančné a štruktúrované tabuľky.
Dataset: FinTabNet (150 DPI rozlíšenie).

Poznámka: TEDS (Table Extraction and Detection Score) meria štruktúru a obsah – Granite-Docling exceluje v exporte do HTML/JSON bez strát.
6. Multimodálne a Celkové Benchmarky. Širšie testy na multimodálne porozumenie.

Poznámka: MMStar testuje multimodálne úlohy (text + obrázok); OCRBench je štandard pre OCR rýchlosť a presnosť. Granite-Docling dosahuje SOTA (state-of-the-art) výsledky pri nízkej latencii (napr. 10-20 minút na dokument na CPU).
Porovnanie s Konkurenciou
- Vs. GOT-OCR 2.0: Granite-Docling má nižší edit distance (0.013 vs. 0.05 v kóde) a lepšiu TEDS (0.97 vs. 0.85), ale je menší (258M vs. 1B+ params).
- Vs. DeepSeek-OCR: Podobná efektivita v token kompresii, ale Granite exceluje v štruktúrovanom výstupe (Markdown/JSON).
- Celkové zlepšenie: Priemerné +20-30 % oproti SmolDocling, s 10x menšou veľkosťou oproti veľkým modelom ako Llama-Vision.
Limity a Budúcnosť
- Limity: Citlivý na halucinácie v malých modeloch; experimentálna podpora pre japončinu/arabčinu. Nie je určený na všeobecné VQA (vizuálne otázky-odpovede).
- Budúcnosť: IBM plánuje integráciu s Granite 4.0 a rozšírenie na grafy/3D dokumenty do 2026. Komunita na Reddit a LinkedIn hlási vysokú presnosť v reálnych testoch (napr. bangalské PDF).
Tieto benchmarky potvrdzujú, prečo je Granite-Docling "game-changer" pre dokumentovú AI – efektívny, presný a open-source.



